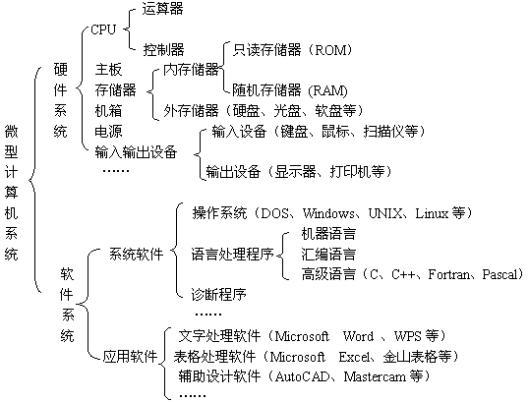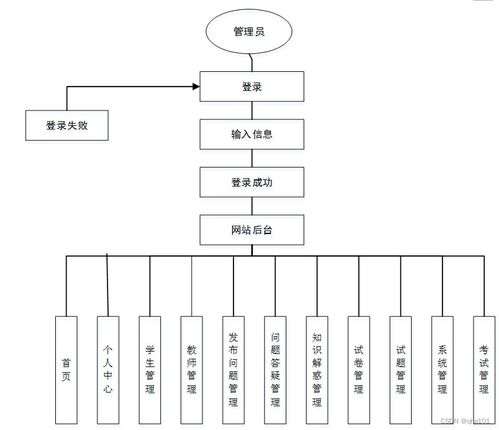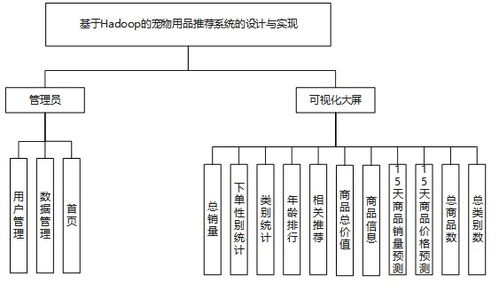
随着宠物经济的蓬勃发展和互联网购物的普及,海量的宠物用品交易数据与用户行为数据不断累积。如何从这些数据中挖掘价值,为宠物主人提供个性化的商品推荐,已成为电商平台提升用户体验与销售转化的关键。本毕业设计项目以大数据技术为核心,旨在设计并实现一个基于Hadoop生态体系的宠物用品智能推荐系统,为大数据专业学习与实践提供一个完整的分析案例。
一、 系统设计目标与架构
- 核心目标:
- 实现海量宠物用品交易数据与用户行为数据的高效存储与处理。
- 构建用户画像与商品画像,精准分析用户偏好与商品特征。
- 设计并实现协同过滤、基于内容的推荐等多种推荐算法模型。
- 通过系统实时或离线地为用户生成个性化推荐列表,提升购物体验。
2. 总体架构:
系统采用经典的分层架构,自下而上包括:
- 数据采集层:通过Web日志、数据库同步、埋点等方式,收集用户浏览、搜索、收藏、购买等行为数据,以及商品属性、库存、评价等静态数据。
- 数据存储与计算层(核心):基于Hadoop分布式文件系统(HDFS)实现原始数据与处理后数据的可靠存储。利用MapReduce、Hive或Spark进行大规模离线批处理分析,使用Spark Streaming或Flink处理实时数据流。此层是数据处理的核心。
- 数据分析与建模层:在存储计算层之上,利用Mahout、Spark MLlib等机器学习库,进行数据清洗、特征工程,并训练协同过滤(如用户-物品协同过滤)、基于内容(根据宠物品种、用品类别、品牌等属性)等推荐模型。
- 业务应用层:提供推荐服务接口,将模型生成的推荐结果(如“猜你喜欢”、“相关推荐”)集成到电商前端应用或移动APP中。
二、 数据处理流程详解(项目核心环节)
数据处理是实现精准推荐的基础,本系统设计了一套完整的数据流水线:
1. 数据采集与导入:
将分散的业务数据库日志、前端日志文件等,通过Sqoop、Flume等工具,准实时或定时地抽取、汇聚并导入HDFS中的原始数据仓库(ODS层)。数据格式可能包括结构化数据(交易记录)、半结构化数据(JSON格式的点击流)等。
2. 数据清洗与预处理:
使用MapReduce作业或Spark作业对原始数据进行清洗。主要任务包括:
- 去除无效记录、重复数据和极端异常值。
- 解析复杂字段(如JSON),提取关键信息。
- 填补缺失值(如使用均值、众数或基于模型的填充方法)。
- 统一数据格式与编码。
清洗后的数据存储在HDFS或Hive数据仓库的明细层(DWD层),为后续分析提供高质量数据源。
3. 特征工程与数据整合:
这是构建推荐模型的关键步骤。在本项目中,需要从清洗后的数据中构建两类核心特征:
- 用户特征:用户ID、人口统计学信息(若可获得)、历史行为统计(如各品类浏览次数、购买频率、平均客单价)、近期兴趣标签(基于浏览序列提取)。
- 物品(宠物用品)特征:商品ID、类别(如主粮、零食、玩具、清洁用品)、适用宠物品种/体型、品牌、价格区间、用户评价情感分、销量等。
需要整合用户-物品交互数据,生成“用户-物品”评分矩阵或隐式反馈矩阵(如浏览时长、购买次数可作为权重)。这一步骤通常在Hive中通过SQL进行多维聚合,或使用Spark DataFrame进行复杂转换。
4. 模型训练与评估:
将处理好的特征数据输入算法模型。例如:
- 协同过滤模型:基于“用户-物品”交互矩阵,计算用户或物品之间的相似度。可以使用Spark MLlib中的交替最小二乘法(ALS)进行矩阵分解,以处理大规模稀疏矩阵。
- 混合模型:结合协同过滤的结果与基于内容的特征(如用户偏好品类与商品类别的匹配度),进行加权融合,以缓解数据稀疏性和冷启动问题。
模型训练后,需使用测试集进行评估,常用指标包括准确率、召回率、F1值、AUC以及商业指标如点击率(CTR)预估。
5. 推荐结果生成与存储:
训练好的模型会对目标用户生成推荐物品列表(如Top-N推荐)。这些结果可以离线批量计算后存入HBase或Redis等低延迟存储中,供应用层快速调用。对于实时性要求高的场景(如实时“看了又看”),可以设计基于实时点击流的快速相似度计算流程。
三、 项目实现关键技术点
- 分布式存储与计算:依靠HDFS和YARN实现数据与计算任务的分布式管理,确保系统可扩展性。
- 数据仓库建模:在Hive中设计维度模型(星型或雪花模型),如以“用户行为事实表”为中心,关联“用户维度表”、“商品维度表”、“时间维度表”等,便于多维度分析。
- 性能优化:在MapReduce/Spark作业中合理设计分区(Partition)、桶(Bucketing)和压缩格式,优化Join操作,提升数据处理效率。
- 冷启动处理:针对新用户或新商品,引入基于热门商品、品类推荐或规则推荐(如新用户注册后推荐促销爆品)作为补充策略。
四、 与展望
本项目通过设计与实现一个完整的基于Hadoop的宠物用品推荐系统,系统性地实践了大数据生命周期中的数据采集、存储、清洗、分析、建模与应用各环节。它不仅巩固了大数据核心技术(HDFS, MapReduce/Spark, Hive等)的应用能力,也深入理解了推荐系统的经典算法与工程架构。可进一步探索引入深度学习模型(如神经网络协同过滤)、利用图计算分析用户-物品关系网络、以及实现更精细化的实时推荐,从而持续提升推荐系统的智能化水平与商业价值。